




As interest in AI explodes throughout the tech industry, it’s important to recognize that the underlying capabilities have been developing gradually over the past several decades. It’s likely that your organization already has much of the necessary architecture in place to advance into AI. It’s also likely that the app dev side of the house knows very little about that architecture. It’s time to get them up to speed.
Feel comfortable with enterprise data storage? Skip to understanding the ML workflow or go straight to the recommendations for scaling AI.
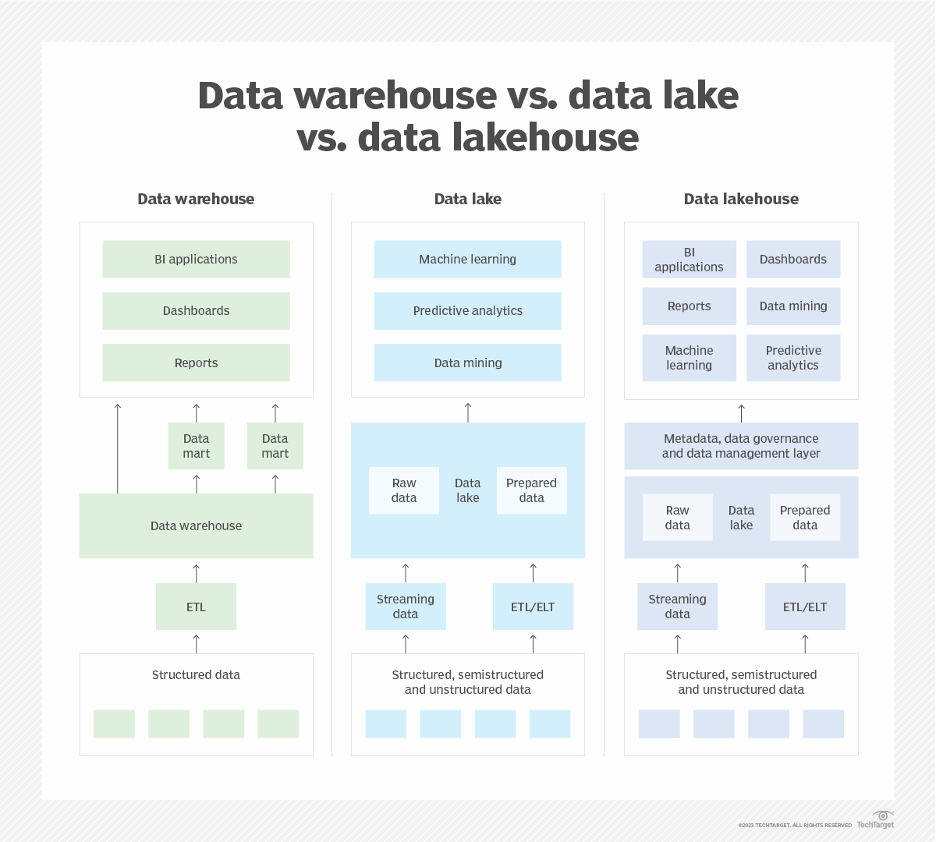
Managing Enterprise Data
Enterprise Data Norm: The Data Warehousing Approach
Data warehouses have been the long-time standard for managing enterprise data. Here, data is routinely gathered from operational sources, combined and structured alongside data from other systems, and used for reporting and analytics.
In most organizations, developers have almost no insight into the warehouse. A standalone group writes the ETL processes to extract the data, transform it to the enterprise model and load it into the warehouse. That group then supports the organization’s reporting needs.
The rise of unstructured data: The Data Lake Approach
The internet age has given enterprises new sources of data. Think IoT streams, text and multimedia files. There’s a lot of this data, and it’s unstructured, meaning that it doesn’t easily fit into a relational schema.
Organizations rarely understood how to use this data immediately, but they knew there were hidden opportunities in it. They started collecting it and loading it into big data repositories called Data Lakes. These data lakes are the domain of data scientists and data engineers – analyzing data, searching it for insights and transforming items into usable data elements for the organizations.
Like the warehouse, most developers are completely hands off from the data lake. As they work with the business and design new applications, they do not know what data is available to them in the lake.
Enter the Data Lakehouse
There are challenges to the data lake approach. First, the data is separate from the warehouse. Data scientists, not surprisingly, want access to all the data. This has led organizations to duplicate data between the lake and warehouse, which can be costly.
More challenging though is organizing the lake. Data scientist teams don’t have a good way to label and track their work even amongst themselves. They often end up duplicating analysis. To scale in the AI age, we need to provide data governance to the unstructured data and tag it with metadata as it is discovered. This is where the data lakehouse steps in.
Data lakehouses provide the combined features of data warehouses and data lakes. Example products in this space include Snowflake, Databricks, Azure Synapse, Google Big Query and Apache Doris.
Lakehouses are fairly new. Organizations have started introducing them over the past three or so years. But still, application developers are usually in the dark.
Machine learning workflow: Supporting a single model
The tools are important and so is understanding how they are used. Let’s look at the work required to produce a single machine learning model.
Stage 1: Data Engineering
To begin, data processing and analysis is done by data scientists and engineers. The goal is to identify data elements that can predict your known historical outcomes.
It’s typical that you will need to augment your data to make accurate connections. For example, you may have sensor readings, but they may combine with weather data to trigger events. You will need to gather weather information to test this idea.
Some of the augmentation may be sophisticated. In one nvisia example, this involved processing video recordings to capture text and create a personality profile of the speaker. These personality metrics were then stored for use in the ML model.
Stage 2: Model Development
With a hypothesis in place from the data engineering stage, the data scientist then creates the model. This is an iterative process that involves selecting a statistical algorithm, training it on a large sample of historical data, and then testing the model with a smaller set of historical data. If your model makes an accurate prediction, it is ready. If not, you iterate through additional data engineering and model development until it works.
Stage 3: Model Production
Once you have a working ML model, you are out of the R&D phase and the real work can begin. You will need to deploy the model (typically as a RESTful web service). Then, integrate it into the apps and data pipelines that will use it.
Once live, monitoring matters. Like any service, you will need to monitor for performance and cost. With AI/ML, you also need to watch for accuracy, bias and drift. Drift is when business circumstances change, such that historical data no longer predicts what you should do in the current environment. You may need to disable the model and go back to the data engineering stage.
Scaling AI in the enterprise: The next step in digital evolution
As seen above, there is a lot of work just to create and manage a single AI model. How can enterprises do this at scale, taking advantage of AI’s potential to remake every aspect of what they do?
Capitalize on your enterprise agility
Realistically, to scale AI enterprises first need the base capabilities that allow them to scale software development in general. Agile business prioritization is essential to prioritize AI opportunities. Flexible systems are required to insert AI models into existing workflows. DevOps techniques enable deployment, monitoring and cross-group information sharing.
You’ve been preparing your organization to adapt to change. That change is here.
(Don’t feel ready and need to take a leap forward? Consider Digital Foundations.)
Scale data engineering with data products
Product-based thinking transformed organizations to think of software in terms of value chains that are continuously improved rather than fixed IT projects. Likewise, we need to start thinking of data analysis as more than a series of throw-away tasks to create a single model. Enter data products.
Recommendation: Take advantage of the data management capabilities of your lakehouse to identify your core data domains (products) and build out a 360 view of them, tagged and cleansed, including structured and unstructured data. Share this view amongst the data science team, throughout IT and with the business. Prioritize the work based on potential business value.

Scale MLOps with Tooling
MLOps is the devops of Machine Learning. It provides automation for model design, deployment, monitoring and governance. It takes so much of the effort out of managing these models. To operate at scale, a tool is essential. Frankly, you’d probably want tooling to ensure quality in managing a single model.

nvisia typically recommends Data Robot for this purpose and recently became a Data Robot partner. We like that it can pull data from a variety of sources, deploy to all the common platforms, integrate with common business tools like SAP and Salesforce, and support reporting in PowerBI or Tableau. The easy access to generative AI tools is also very exciting.

It's important to note that there are other, open source products that may fit your use case. Google Kubeflow and Netflix Metaflow come to mind.
Check your infrastructure for pub-sub and queues
During the data engineering stage, raw data was mined and processed to train the ML model. This may have been sophisticated, for example capturing text from video and doing AI analysis on it.
In production, you feed new incoming data to the model to make predictions. This requires processing the raw data at runtime, transforming and augmenting it as it comes in, to gather the necessary inputs for your model. You will most likely want to do this asynchronously, and therefore need to have solid pub-sub or queuing infrastructure in place, such as Confluent / Kafka or RabbitMQ.
Conclusion
There are several steps an organization can take now to ensure they are ready for the AI demands of their business.
- Build on your agile and devops capabilities
- Prioritize your data domains and features
- Identify their 360 views as data products
- Specify and share the metadata to define them
- Select an ML Ops platform
- Have your pub-sub / queuing infrastructure ready
With these items in place, AI is no longer a special capability limited to one corner of your organization. All of your teams have the tools they need to innovate with AI.