




Part 1 of 3
Introduction
I’ve been getting re-acquainted with SQL Server 2016 after a very long hiatus (read 7.0). While I’ve used SQL Server on many projects throughout the years, I’ve tended towards Oracle, DB2, and Postgres due to either more advanced features or price (in the case of Postgres). Recently, I had the opportunity to take a much more in-depth look at SQL Server 2016. A few capabilities struck me as significant to our clients’ needs: columnstore indexes, in-memory tables and indexed views (aka materialized views). In the first of three blog posts, I’ll cover columnar indexes. I’ll cover in-memory tables in the second installment and indexed views in the last one.
Columnstore Indexes in SQL Server
Data in SQL Server (and virtually every other RDBMS) is stored in rows, with attributes being stored as columns. This works very well for storing normalized data for use by OLTP systems (optimizing write performance) and to a lesser extent by de-normalized data in OLAP systems. Conversely, data can also be stored in columns, where rows consist of pointers to the relevant columns of data. This columnar approach is best when there is a relatively small distribution of data values as the data is not stored redundantly for every row, which allows these columns of data to take advantage of compression which can reduce storage by upwards of 90%. It is worth noting that read performance is optimized, while write performance can suffer, making it ideal for OLAP workloads. An interesting twist on SQL Server’s columnstore index (as opposed to columnar databases), is that not only do they apply for tables used for reporting purposes, they can also be applied to OLTP serving tables in support of real-time analytics.
Using an example database from Microsoft (https://github.com/Microsoft/sql-server-samples/
releases/tag/wide-world-importers-v1.0 ), the WideWorldImporters database, consider the following conceptual views of row vs columnar storage.
Please note that the table definitions are shown in the Appendix.
|
Customer ID |
Customer Name |
Customer Category ID |
Delivery Method ID |
Phone Number |
Payment Days |
|
1 |
Tailspin Toys |
3 |
3 |
210.555.0100 |
7 |
|
486 |
Wingtip Toys |
3 |
3 |
216.555.0100 |
7 |
|
645 |
Raj Verma |
7 |
3 |
203.555.0100 |
7 |
Figure 1 – Conceptual row storage
Please note that DBCC DROPCLEANBUFFERS is used to clear the cache before running any of the queries to ensure no cached data is used, thus forcing the query optimizer to use indexes as it deems necessary to execute the query.
SELECT PackageTypeName, [OrderLines].PackageTypeID, count(OrderLineID) as '# of orders' from [Sales].[OrderLines]
INNER JOIN [Warehouse].[PackageTypes] on OrderLines.PackageTypeID = PackageTypes.PackageTypeID
GROUP BY PackageTypeName, [OrderLines].PackageTypeID;
https://github.com/NVISIA/mvogt-blog-code/blob/master/query.sql
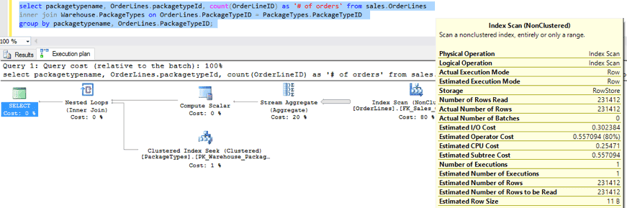
Note that the bulk of the time (80%) is spent performing an index scan to group the PackageTypeID’s.
Now, let’s create a columnstore index on the items in the query.
CREATE NONCLUSTERED COLUMNSTORE INDEX NCCX_SALES_ORDERLINES_PKGTYPE ON Sales.OrderLines
(
PackageTypeId,
OrderLineID
);
https://github.com/NVISIA/mvogt-blog-code/blob/master/createColumnstoreIndex.sql
|
Customer ID |
1 |
486 |
645 |
|
Customer Name |
Tailspin Toys |
Wingtip Toys |
Raj Verma |
|
Customer Category ID |
3 |
7 |
|
|
Delivery Method ID |
3 |
|
|
|
Phone Number |
210.555.0100 |
216.555.0100 |
203.555.0100 |
|
Payment Days |
7 |
|
|
|
Row Group |
1 |
1 |
1 |
Figure 2 – Conceptual columnar storage
| packagetypename | packagetypeId | # of orders |
| Bag | 1 | 1036 |
| Packet | 9 | 5209 |
| Each | 7 | 220955 |
| Paid | 10 | 4212 |
| ); |
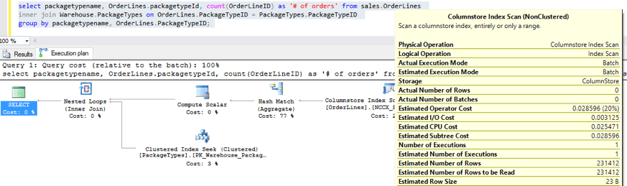
Note that the bulk of the time (77%) is spent performing a hash match, while the new columnstore index scan to group the PackageTypeID’s uses 20% (down from the original 80% row index scan).
Care must be taken when applying indexes, including those of the columnstore type, as they negatively impact write performance and occupy disk space.
This concludes the first of three blog posts on new features in SQL Server. The next two will cover in-memory tables and indexed views (aka materialized views).
Appendix
Required DDL for tables
https://github.com/NVISIA/mvogt-blog-code/blob/master/required_ddl.sql
Optional DDL for tables
https://github.com/NVISIA/mvogt-blog-code/blob/master/optional_ddl.sql