



I attended a free full day event on Apache Cassandra on April 9th. It was held at the Chicago Sheraton Hotel and Tower and was sponsored by Microsoft Azure, HP and Vormetric Data Security. They provided free breakfast, free lunch, a free t-shirt (I managed to get two by the way) and other free goodies. Not surprisingly, there were many fans of free stuff that attended Cassandra Day. My estimation would be over 400. It was a well organized event, providing a great environment to network and learn more about Cassandra. Did I mention this was free?
The event was broken down into three separate tracks; beginner, tech deep dive/use cases session and the internet enterprise executive summit. Being new to Cassandra I attended the beginner session.
So what is Cassandra and why the hype. Cassandra is an open source distributed database management system designed to handle large amounts of data across many commodity servers. In the introductory session, the so called technical evangelists highlight Cassandra as being a fast, highly available and scalable store with predictable performance. The architecture itself does not condone the master/slave concept. Instead it utilizes a hash ring architecture where every node is equal, data is replicated and partitioned around a ring and that data resides in that ring. Write operations are written to any node in the cluster or coordinator which also includes a timestamp of each write. Data is replicated among various nodes to maintain availability of that data in case of node failure. Initially written to a commit log (ensuring a durable write) and then to a memtable. Once the memtable fills, it gets flushed to disk to SSTables (sorted string table). These SSTables are immutable data files to which Cassandra writes memtables periodically. SSTables are append only and stored on disk sequentially and maintained for each Cassandra table. Periodically, the SSTables are merged and compacted keeping the latest timestamp.
No data is physically deleted. Instead, data in a Cassandra column can have an optional expiration date called TTL (time to live) which is then marked with a tombstone. The data marked with tombstone will then be physically delete during a normal compaction process.
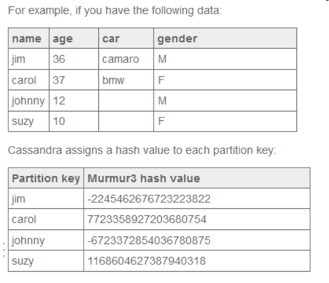
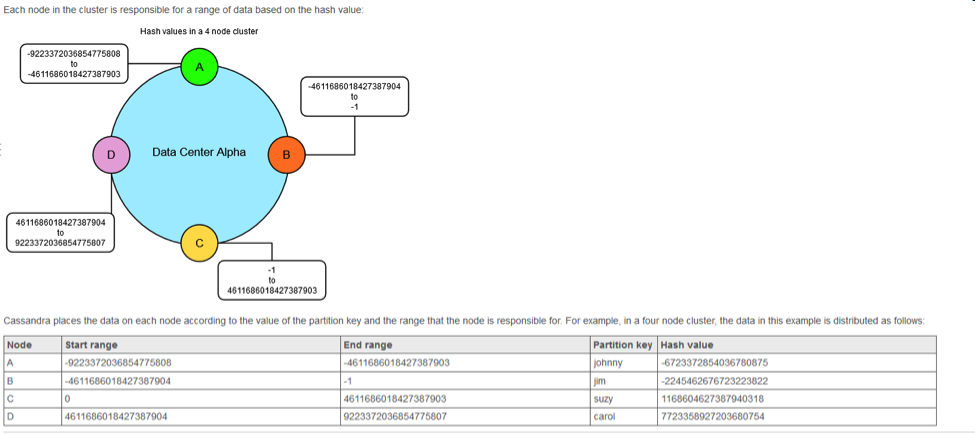
DataStax has some good documentation around their product that can be found in planetcassandra.org. I took a snippet of their data distribution or consistent hashing architecture. Consistent hashing partitions data based on the partition key.
Cassandra Query Language (CQL) is the default and primary interface into the Cassandra DBMS. Using CQL is similar to using SQL (Structured Query Language). CQL and SQL share the same abstract idea of a table constructed of tables and rows. The main difference from SQL is that Cassandra does not support joins, sub queries or aggregations. You can use CQL to create physical tables as well have common properties such as text, int, decimal and blob.
I also attended an Introduction to Data Modeling with Apache Cassandra session and found some key differences between your typical RDMS mind sight versus the modeling mind sight in Cassandra. In Cassandra, denormalized tables to eliminate joins and foreign keys is the preferred modeling model. Granted, denormalized tables would enhance performance quite a bit but seems to put a lot more onus on the data modeler and database developers to constantly make changes as applications change. Any updates to rows would need to update across all area/columns that need to change. The technical evangelists did say that in Cassandra modeling, design of the models are based on applications as opposed to domain data. As requirements drive changes to applications, models must change to meet the data demands of the application.
In the RDMS world, adherence to ACID (atomicity, consistency, isolation and durability) principles guarantees repeatable, deterministic behavior and helps ensures data safety in case of failure. From lessons learned, the Cassandra technical evangelists feel consistency is not practical and is performance-limiting as databases scales.
These were just a few points of the Cassandra event I found interesting and definitely different from your traditional RDMS design. They also offered a free download (free is always good) and jump drive to kick the tires. I haven’t tried this out yet but will soon enough. They also said the recorded presentations will be open to the public in planetcassandra.com very soon. I hope to see that as there was an advanced modeling session I didn’t get to attend. Overall, the event was thought provoking and well organized and I would be very open to playing around with the product.
For Additional Blog Post please check out NVISIA's Enterprise Data Management Page